

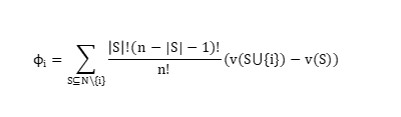 |
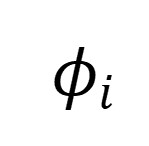 |
 |
 |
摘要:在“双碳”政策背景下,本文构建了融合财务、绿色及供应链的多维指标评估体系。综合比较九种机器学习模型发现逻辑回归模型综合性能最优(准确率0.880,AUC 0.89)。消融实验证实,引入绿色指标可使F1值提升6.7%。SHAP分析揭示ESG评分均值、ESG评分均值标准差较上年及供应商集中度为三大关键绿色风险因子。
引言
近年来,随着全球“碳中和”进程的不断推进,我国政府相继出台了《关于加快推动制造业绿色化发展的指导意见》等一系列政策,明确绿色发展将成为推动经济高质量发展的核心动力。在此背景下,构建一个能够更加全面、动态评估绿色供应链风险的新型信用评估体系具有重要的理论和实践意义。在传统财务指标基础上,该体系需要综合考量企业的环境绩效、供应链管理水平以及绿色技术创新能力等多方面因素,形成统一、透明且可解释的风险评价标准,为金融机构在绿色转型过程中精准预测和量化企业信用风险提供科学依据。本研究重点关注以下核心问题:
1.在绿色供应链背景下,哪些非财务指标能有效评估中小企业的信用风险?
2.如何构建既精准又透明可解释的风险评估模型?
3.金融机构如何运用可解释机器学习模型优化绿色信贷决策,助力中小企业破解融资难题?
一、研究方法
本研究基于可解释机器学习技术,构建了一个融合财务指标、绿色指标和供应链指标的多维信用风险评估体系。研究方法采用“数据透明化―模型优选―归因解释”的三步递进式框架,具体架构如下:
(一)数据来源与处理
本研究采用Altman的Z-score模型,将Z-score值低于1.81的企业界定为违约企业(因变量=1),其余为非违约企业(因变量=0)。研究样本选取工业和信息化部公布的绿色供应链管理企业及其上游A股上市的一、二级供应商。对于2000-2024年间发生违约的企业,我们采集其违约前一年(T-1年)的财务数据,并排除在成为核心供应商前已违约的企业;对于未违约企业,则选取其成为核心供应商当年的数据作为基准年(T-1年)。数据来源于工业节能与绿色发展管理平台及CSMAR数据库,最终样本包含250家企业,其中违约样本84个,占比33.6%。
本研究构建的信用风险评估体系包含财务指标、绿色指标和供应链指标三大类,共计26个特征变量。各指标的具体定义及数据来源详见表1。
在模型训练之前,将收集的全部样本数据按照7:3的比例随机划分为训练集和测试集,训练集包含175个样本,测试集包含75个样本。针对数值型变量的缺失值采用中位数填补,降低极端值带来的偏差影响;使用Z-Score方法,以±3倍标准差为阈值进行异常值检测,并使用盖帽法超出阈值的数据替换为对应的边界值。特征筛选采用方差膨胀因子(VIF)指标,剔除VIF>5的变量,避免多重共线性。针对连续变量进行Z-score标准化,消除量纲影响。最后采用带交叉验证的递归特征消除方法(RFECV)进行特征筛选。以随机森林分类器为基础模型,通过100折分层交叉验证评估特征子集性能,最终筛选出交叉验证得分最高的特征子集作为输入模型的最终数据集。
(二)模型选择与训练
基于预处理后的数据集,本研究系统评估了九种主流机器学习模型的性能表现,包括支持向量机(SVC)、决策树、随机森林、朴素贝叶斯、AdaBoost、逻辑回归、KNN、梯度提升和神经网络。通过网格搜索方法得到每种模型的最优参数,并对比模型测试数据集上的表现。本研究采用ROC曲线、AUC值、准确率、精确率、召回率和F1值等多项指标进行综合评估。
(三)可解释性分析:SHAP框架
SHAP方法源自合作博弈论,通过精确计算每个特征对模型预测结果的边际影响,量化其特征重要性。
其中:
=特征中i的SHAP值;
V(S)=子集S的模型输出;
N=全部特征集合。
SHAP方法显著优于传统技术,不仅解决了局部解释不稳定的问题,还能实现三大核心功能:全局特征重要性排序、个体样本归因分析以及绿色指标非线性效应的可视化呈现。
二、数据分析与结果
(一)模型性能对比
模型性能对比结果如图1所示,逻辑回归表现最为突出,其准确率达到0.880,F1值为0.871,均优于其他模型。此外,该模型的AUC值高达0.89(表2),明显优于排名第二的神经网络模型(AUC=0.87)。
逻辑回归模型在本研究中的优异表现,可以归因于以下三方面因素:首先,由于特征维度较少且不存在交互效应,树模型复杂的结构容易导致过拟合,而逻辑回归模型通过L2正则化有效控制了模型复杂度;其次,样本量较小限制了SVC等非线性模型学习复杂模式的能力;最后,决策树模型在训练样本不足时出现明显欠拟合,导致其准确率最低。
为验证绿色指标对模型性能的提升效果,本研究采用消融实验方法:从最终模型中剔除所有绿色指标相关特征,仅保留财务指标,重新训练逻辑回归模型。对比实验结果显示,包含绿色指标的最终模型在预测性能上显著优于仅含财务指标的简化模型。
如表3所示,相较于仅包含财务值标的基础模型,增加绿色指标后,模型的F1值从0.75提升至0.876,增幅达到16.8%。说明绿色指标的引入能够显著提升传统财务指标模型的预测能力。
(二)SHAP分析解释结果
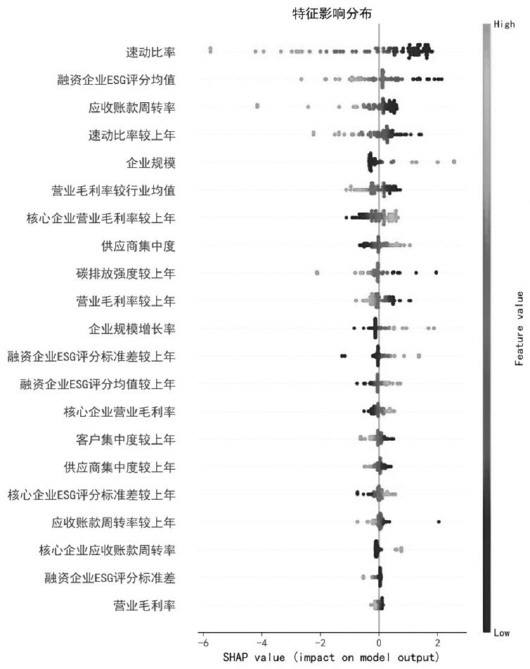
图1 SHAP蜂群图
图1的SHAP蜂群图直观呈现了各特征对模型预测结果的影响程度及方向。横轴SHAP值代表特征影响力,每个样本点以不同颜色标注特征值高低:浅色表示高值,深色表示低值。样本点分布在X轴右侧时,表明该特征会提升违约风险。分析发现以下关键规律:首先,速动比率、应收账款周转率等财务指标仍然对模型有较大贡献,且预测结果符合预期。其次,ESG评分均值(SHAP均值=0.68)作为第二大风险因子,其贡献度超越了除速动比率外的所有传统财务指标。低ESG评分样本(深色点)集中于SHAP正值区,验证了绿色金融政策对风险管控的积极作用; ESG评分波动增大可能反映出企业绿色管理失衡,可作为风险预警指标。此外,供应商集中度的浅色点主要分布在右侧,表明供应链依赖度过高会导致违约风险上升,符合核心企业风险传导理论。最后,绿色指标整体贡献率达模型总解释力的23.1%,不仅展现出突出的预测能力,其作用方向也与政策导向高度吻合。
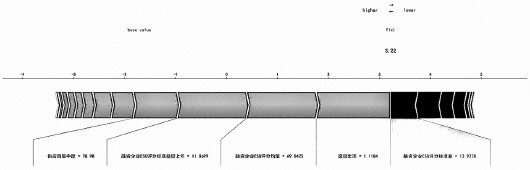
图2 SHAP力图
图2的SHAP力图直观量化了各特征对预测结果的贡献程度。图中基准值代表全体样本的平均预测值,浅色箭头表示提升预测值的正向特征,深色箭头则代表降低预测值的负向特征,箭头长度精确反映了特征影响力的大小。以南宁八菱科技股份有限公司为例,作为广西柳工机械股份有限公司的上游供应商,分析显示影响其违约风险的四大关键因素依次为:速动比率、融资企业ESG评分均值、ESG评分年度标准差变化以及供应链集中度。基于这些特征的综合评估,模型最终判定该企业具有较高的违约风险。
绿色指标的引入为传统财务主导的信用评估体系提供了重要补充。金融机构可将ESG评分动态变化、供应链集中度等绿色供应链指标纳入现有信贷风险模型,构建结合财务指标有绿色供应链特色指标的多余预警机制,实现对风险传导的精准预判和有效防控。
三、结论与展望
本研究构建了一套完整的绿色供应链中小企业信用风险评估体系,通过对比分析多种机器学习模型,在预测精度和可解释性方面取得了重要突破。核心研究成果包括:
逻辑回归模型在小样本数据预测中表现优异,其预测精度优于其他复杂模型。该模型还具有显著的可解释性优势,能够满足金融风控领域的监管合规要求,尤其适合需要明确解释模型决策逻辑的金融应用场景。
研究发现,绿色供应链信用风险的关键驱动因素主要包括ESG评分均值及其波动性、供应商集中度等指标。通过SHAP值归因分析,我们不仅识别出这些核心影响因素,还构建了符合《商业银行资本管理办法》要求的透明化模型解释框架。这一方法显著提升了金融机构传统风险模型的可解释性,为监管审计提供了更可靠的依据。
本研究虽取得阶段性成果,但仍需在以下方面深入探索:
样本扩展与数据丰富。当前研究聚焦于国内上市公司,后续可拓展至非上市公司环保处罚数据及国际供应链ESG记录,构建跨链条风险全景视图,更完整地刻画供应链金融风险特征。未来研究还可探索多模态数据融合方法,开发智能化程度更高的风险评估体系。
建立动态风险监测预警机制。当前评估指标过度依赖静态年报数据,建议引入区块链技术实现绿色指标的实时动态监测,及时预警政策调整对中小企业偿债能力的影响,从而显著提升风险评估的时效性和准确性。同时,建议监管部门开发轻量化监管科技工具,专门适配中小企业需求,有效降低其数字化转型门槛。
表1 信用风险评估变量体系
指标分类 指标名称
财务指标 应收账款周转率
速动比率
营业毛利率
产品竞争力(主营业务收入行业赫芬达尔指数)
营业毛利率较行业均值
营业收入较上年增长率
企业规模较上年增长率
应收账款周转率较上年
营业毛利率较上年
速动比率较上年
核心企业应收账款周转率
核心企业营业毛利率
核心企业速动比率
核心企业应收账款周转率较上年
核心企业速动比率较上年
绿色指标 融资企业ESG评分均值
融资企业ESG评分标准差
人均绿色专利数
碳排放强度较上年
核心企业ESG评分均值
核心企业ESG评分标准差
核心企业ESG评分均值较上年
核心企业ESG评分标准差较上年
供应链指标 供应商集中度
客户集中度较上年
供应商集中度较上年
表2 模型性能对比
Logistic Regression SVC Neural Network Gradient Boosting AdaBoost KNN Random Forest Naive Bayes Decision Tree
Accuracy 0.880 0.827 0.800 0.787 0.787 0.760 0.760 0.747 0.667
Precision 0.882 0.824 0.802 0.783 0.787 0.824 0.760 0.749 0.714
Recall 0.880 0.827 0.800 0.787 0.787 0.760 0.760 0.747 0.667
F1-Score 0.876 0.824 0.801 0.784 0.787 0.711 0.760 0.748 0.676
AUC 0.89 0.88 0.87 0.82 0.82 0.81 0.84 0.76 0.70
表3 消融实验模型对比
Accuracy Precision Recall F1 Score
最终模型 0.880 0.882 0.870 0.876
财务指标模型 0.840 0.783 0.720 0.750
引言
近年来,随着全球“碳中和”进程的不断推进,我国政府相继出台了《关于加快推动制造业绿色化发展的指导意见》等一系列政策,明确绿色发展将成为推动经济高质量发展的核心动力。在此背景下,构建一个能够更加全面、动态评估绿色供应链风险的新型信用评估体系具有重要的理论和实践意义。在传统财务指标基础上,该体系需要综合考量企业的环境绩效、供应链管理水平以及绿色技术创新能力等多方面因素,形成统一、透明且可解释的风险评价标准,为金融机构在绿色转型过程中精准预测和量化企业信用风险提供科学依据。本研究重点关注以下核心问题:
1.在绿色供应链背景下,哪些非财务指标能有效评估中小企业的信用风险?
2.如何构建既精准又透明可解释的风险评估模型?
3.金融机构如何运用可解释机器学习模型优化绿色信贷决策,助力中小企业破解融资难题?
一、研究方法
本研究基于可解释机器学习技术,构建了一个融合财务指标、绿色指标和供应链指标的多维信用风险评估体系。研究方法采用“数据透明化―模型优选―归因解释”的三步递进式框架,具体架构如下:
(一)数据来源与处理
本研究采用Altman的Z-score模型,将Z-score值低于1.81的企业界定为违约企业(因变量=1),其余为非违约企业(因变量=0)。研究样本选取工业和信息化部公布的绿色供应链管理企业及其上游A股上市的一、二级供应商。对于2000-2024年间发生违约的企业,我们采集其违约前一年(T-1年)的财务数据,并排除在成为核心供应商前已违约的企业;对于未违约企业,则选取其成为核心供应商当年的数据作为基准年(T-1年)。数据来源于工业节能与绿色发展管理平台及CSMAR数据库,最终样本包含250家企业,其中违约样本84个,占比33.6%。
本研究构建的信用风险评估体系包含财务指标、绿色指标和供应链指标三大类,共计26个特征变量。各指标的具体定义及数据来源详见表1。
在模型训练之前,将收集的全部样本数据按照7:3的比例随机划分为训练集和测试集,训练集包含175个样本,测试集包含75个样本。针对数值型变量的缺失值采用中位数填补,降低极端值带来的偏差影响;使用Z-Score方法,以±3倍标准差为阈值进行异常值检测,并使用盖帽法超出阈值的数据替换为对应的边界值。特征筛选采用方差膨胀因子(VIF)指标,剔除VIF>5的变量,避免多重共线性。针对连续变量进行Z-score标准化,消除量纲影响。最后采用带交叉验证的递归特征消除方法(RFECV)进行特征筛选。以随机森林分类器为基础模型,通过100折分层交叉验证评估特征子集性能,最终筛选出交叉验证得分最高的特征子集作为输入模型的最终数据集。
(二)模型选择与训练
基于预处理后的数据集,本研究系统评估了九种主流机器学习模型的性能表现,包括支持向量机(SVC)、决策树、随机森林、朴素贝叶斯、AdaBoost、逻辑回归、KNN、梯度提升和神经网络。通过网格搜索方法得到每种模型的最优参数,并对比模型测试数据集上的表现。本研究采用ROC曲线、AUC值、准确率、精确率、召回率和F1值等多项指标进行综合评估。
(三)可解释性分析:SHAP框架
SHAP方法源自合作博弈论,通过精确计算每个特征对模型预测结果的边际影响,量化其特征重要性。
其中:
=特征中i的SHAP值;
V(S)=子集S的模型输出;
N=全部特征集合。
SHAP方法显著优于传统技术,不仅解决了局部解释不稳定的问题,还能实现三大核心功能:全局特征重要性排序、个体样本归因分析以及绿色指标非线性效应的可视化呈现。
二、数据分析与结果
(一)模型性能对比
模型性能对比结果如图1所示,逻辑回归表现最为突出,其准确率达到0.880,F1值为0.871,均优于其他模型。此外,该模型的AUC值高达0.89(表2),明显优于排名第二的神经网络模型(AUC=0.87)。
逻辑回归模型在本研究中的优异表现,可以归因于以下三方面因素:首先,由于特征维度较少且不存在交互效应,树模型复杂的结构容易导致过拟合,而逻辑回归模型通过L2正则化有效控制了模型复杂度;其次,样本量较小限制了SVC等非线性模型学习复杂模式的能力;最后,决策树模型在训练样本不足时出现明显欠拟合,导致其准确率最低。
为验证绿色指标对模型性能的提升效果,本研究采用消融实验方法:从最终模型中剔除所有绿色指标相关特征,仅保留财务指标,重新训练逻辑回归模型。对比实验结果显示,包含绿色指标的最终模型在预测性能上显著优于仅含财务指标的简化模型。
如表3所示,相较于仅包含财务值标的基础模型,增加绿色指标后,模型的F1值从0.75提升至0.876,增幅达到16.8%。说明绿色指标的引入能够显著提升传统财务指标模型的预测能力。
(二)SHAP分析解释结果
图1 SHAP蜂群图
图1的SHAP蜂群图直观呈现了各特征对模型预测结果的影响程度及方向。横轴SHAP值代表特征影响力,每个样本点以不同颜色标注特征值高低:浅色表示高值,深色表示低值。样本点分布在X轴右侧时,表明该特征会提升违约风险。分析发现以下关键规律:首先,速动比率、应收账款周转率等财务指标仍然对模型有较大贡献,且预测结果符合预期。其次,ESG评分均值(SHAP均值=0.68)作为第二大风险因子,其贡献度超越了除速动比率外的所有传统财务指标。低ESG评分样本(深色点)集中于SHAP正值区,验证了绿色金融政策对风险管控的积极作用; ESG评分波动增大可能反映出企业绿色管理失衡,可作为风险预警指标。此外,供应商集中度的浅色点主要分布在右侧,表明供应链依赖度过高会导致违约风险上升,符合核心企业风险传导理论。最后,绿色指标整体贡献率达模型总解释力的23.1%,不仅展现出突出的预测能力,其作用方向也与政策导向高度吻合。
图2 SHAP力图
图2的SHAP力图直观量化了各特征对预测结果的贡献程度。图中基准值代表全体样本的平均预测值,浅色箭头表示提升预测值的正向特征,深色箭头则代表降低预测值的负向特征,箭头长度精确反映了特征影响力的大小。以南宁八菱科技股份有限公司为例,作为广西柳工机械股份有限公司的上游供应商,分析显示影响其违约风险的四大关键因素依次为:速动比率、融资企业ESG评分均值、ESG评分年度标准差变化以及供应链集中度。基于这些特征的综合评估,模型最终判定该企业具有较高的违约风险。
绿色指标的引入为传统财务主导的信用评估体系提供了重要补充。金融机构可将ESG评分动态变化、供应链集中度等绿色供应链指标纳入现有信贷风险模型,构建结合财务指标有绿色供应链特色指标的多余预警机制,实现对风险传导的精准预判和有效防控。
三、结论与展望
本研究构建了一套完整的绿色供应链中小企业信用风险评估体系,通过对比分析多种机器学习模型,在预测精度和可解释性方面取得了重要突破。核心研究成果包括:
逻辑回归模型在小样本数据预测中表现优异,其预测精度优于其他复杂模型。该模型还具有显著的可解释性优势,能够满足金融风控领域的监管合规要求,尤其适合需要明确解释模型决策逻辑的金融应用场景。
研究发现,绿色供应链信用风险的关键驱动因素主要包括ESG评分均值及其波动性、供应商集中度等指标。通过SHAP值归因分析,我们不仅识别出这些核心影响因素,还构建了符合《商业银行资本管理办法》要求的透明化模型解释框架。这一方法显著提升了金融机构传统风险模型的可解释性,为监管审计提供了更可靠的依据。
本研究虽取得阶段性成果,但仍需在以下方面深入探索:
样本扩展与数据丰富。当前研究聚焦于国内上市公司,后续可拓展至非上市公司环保处罚数据及国际供应链ESG记录,构建跨链条风险全景视图,更完整地刻画供应链金融风险特征。未来研究还可探索多模态数据融合方法,开发智能化程度更高的风险评估体系。
建立动态风险监测预警机制。当前评估指标过度依赖静态年报数据,建议引入区块链技术实现绿色指标的实时动态监测,及时预警政策调整对中小企业偿债能力的影响,从而显著提升风险评估的时效性和准确性。同时,建议监管部门开发轻量化监管科技工具,专门适配中小企业需求,有效降低其数字化转型门槛。
表1 信用风险评估变量体系
指标分类 指标名称
财务指标 应收账款周转率
速动比率
营业毛利率
产品竞争力(主营业务收入行业赫芬达尔指数)
营业毛利率较行业均值
营业收入较上年增长率
企业规模较上年增长率
应收账款周转率较上年
营业毛利率较上年
速动比率较上年
核心企业应收账款周转率
核心企业营业毛利率
核心企业速动比率
核心企业应收账款周转率较上年
核心企业速动比率较上年
绿色指标 融资企业ESG评分均值
融资企业ESG评分标准差
人均绿色专利数
碳排放强度较上年
核心企业ESG评分均值
核心企业ESG评分标准差
核心企业ESG评分均值较上年
核心企业ESG评分标准差较上年
供应链指标 供应商集中度
客户集中度较上年
供应商集中度较上年
表2 模型性能对比
Logistic Regression SVC Neural Network Gradient Boosting AdaBoost KNN Random Forest Naive Bayes Decision Tree
Accuracy 0.880 0.827 0.800 0.787 0.787 0.760 0.760 0.747 0.667
Precision 0.882 0.824 0.802 0.783 0.787 0.824 0.760 0.749 0.714
Recall 0.880 0.827 0.800 0.787 0.787 0.760 0.760 0.747 0.667
F1-Score 0.876 0.824 0.801 0.784 0.787 0.711 0.760 0.748 0.676
AUC 0.89 0.88 0.87 0.82 0.82 0.81 0.84 0.76 0.70
表3 消融实验模型对比
Accuracy Precision Recall F1 Score
最终模型 0.880 0.882 0.870 0.876
财务指标模型 0.840 0.783 0.720 0.750